Normalization

Description of normalization
Database normalization is a crucial process in Microsoft Access to optimize database design. It involves organizing tables and relationships to reduce redundancy and dependency. The primary goals are to eliminate duplicate data, ensure data integrity, and enhance performance. The process is typically carried out in stages, known as normal forms, each addressing specific types of issues. Proper normalization results in a more efficient and maintainable database structure, leading to improved data accuracy and easier updates.

First normal form (1NF)
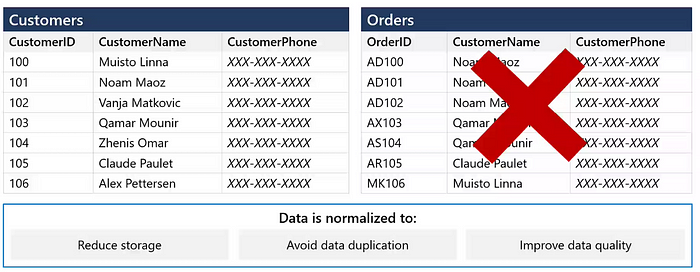
Ensures unique data by eliminating duplicate columns and creating separate tables for each group of related data.
Eliminate repeating groups in individual tables.
Create a separate table for each set of related data.
Identify each set of related data with a primary key.
Do not use multiple fields in a single table to store similar data. For example, to track an inventory item that may come from two possible sources, an inventory record may contain fields for Vendor Code 1 and Vendor Code 2.
What happens when you add a third vendor? Adding a field is not the answer; it requires program and table modifications and does not smoothly accommodate a dynamic number of vendors. Instead, place all vendor information in a separate table called Vendors, then link inventory to vendors with an item number key, or vendors to inventory with a vendor code key.
Second normal form (2NF)
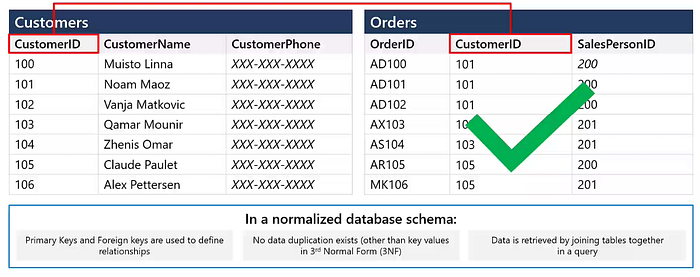
Builds on 1NF by removing subsets of data that apply to multiple rows and placing them in separate tables.
Create separate tables for sets of values that apply to multiple records.
Relate these tables with a foreign key.
Records should not depend on anything other than a table’s primary key (a compound key, if necessary). For example, consider a customer’s address in an accounting system. The address is needed by the Customers table, but also by the Orders, Shipping, Invoices, Accounts Receivable, and Collections tables. Instead of storing the customer’s address as a separate entry in each of these tables, store it in one place, either in the Customers table or in a separate Addresses table.
Third normal form(3NF)
Removes columns not dependent on the primary key.
- Eliminate fields that do not depend on the key.
Values in a record that are not part of that record’s key do not belong in the table. In general, anytime the contents of a group of fields may apply to more than a single record in the table, consider placing those fields in a separate table.
For example, in an Employee Recruitment table, a candidate’s university name and address may be included. But you need a complete list of universities for group mailings. If university information is stored in the Candidates table, there is no way to list universities with no current candidates. Create a separate Universities table and link it to the Candidates table with a university code key.
EXCEPTION: Adhering to the third normal form, while theoretically desirable, is not always practical. If you have a Customers table and you want to eliminate all possible interfield dependencies, you must create separate tables for cities, ZIP codes, sales representatives, customer classes, and any other factor that may be duplicated in multiple records. In theory, normalization is worth pursing. However, many small tables may degrade performance or exceed open file and memory capacities.
It may be more feasible to apply third normal form only to data that changes frequently. If some dependent fields remain, design your application to require the user to verify all related fields when any one is changed.
Other normalization forms
Fourth normal form, also called Boyce Codd Normal Form (BCNF), and fifth normal form do exist, but are rarely considered in practical design. Disregarding these rules may result in less than perfect database design, but should not affect functionality.
Denormalization
While the third normal form is theoretically desirable, it is not always possible for all data. In addition, a normalized database does not always give you the best performance. Normalized data frequently requires multiple join operations to get all the necessary data returned in a single query. There is a tradeoff between normalizing data when the number of joins required to return query results has high CPU utilization, and denormalized data that has fewer joins and less CPU required, but opens up the possibility of update anomalies.
Note — Denormalized data is not the same as unnormalized. For denormalization, we start by designing tables that are normalized. Then we can add additional columns to some tables to reduce the number of joins required, but as we do so, we are aware of the possible update anomalies. We then make sure we have triggers or other kinds of processing that will make sure that when we perform an update, all the duplicate data is also updated.
Denormalized data can be more efficient to query, especially for read heavy workloads like a data warehouse. In those cases, having additional columns may offer better query patterns and/or more simplistic queries.
Star schema
While most normalization is aimed at OLTP workloads, data warehouses have their own modeling structure, which is usually a denormalized model. This design uses fact tables, which record measurements or metrics for specific events like a sale, and joins them to dimension tables, which are smaller in terms of row count, but may have a large number of columns to describe the fact data. Some example dimensions would include inventory, time, and/or geography. This design pattern is used to make the database easier to query and offer performance gains for read workloads.
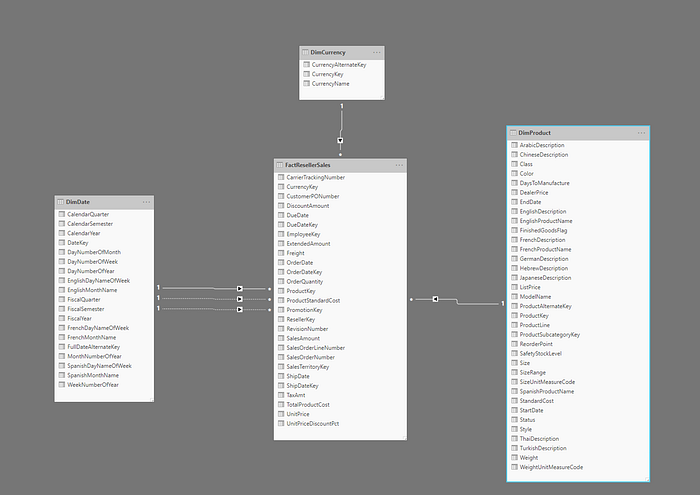
The above image shows an example of a star schema, including a FactResellerSales fact table, and dimensions for date, currency, and products. The fact table contains data related to the sales transactions, and the dimensions only contain data related to a specific element of the sales data. For example, the FactResellerSales table contains only a ProductKey to indicate which product was sold. All of the details about each product is stored in the DimProduct table, and related back to the fact table with the ProductKey column.
Related to star schema design is a snowflake schema, which uses a set of more normalized tables for a single business entity. The following image shows an example of a single dimension for a snowflake schema. The Products dimension is normalized and stored in three tables called DimProductCategory, DimProductSubcategory, and DimProduct.
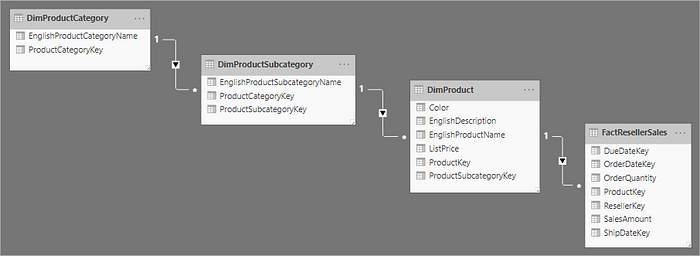
The main difference between star and snowflake schemas is that the dimensions in a snowflake schema are normalized to reduce redundancy, which saves storage space. The tradeoff is that your queries require more joins, which can increase your complexity and decrease performance.




